
Python dataclass 语法详解:field、default_factory、slots 与常见坑
面向只学过 class 和 __init__() 的新手,从 dataclass 的作用讲起,逐步解释 __repr__()、__eq__()、field、default_factory、kw_only、slots、frozen、match_args 与常用辅助函数。
Pythondataclass
面向只学过 class 和 __init__() 的新手,从 dataclass 的作用讲起,逐步解释 __repr__()、__eq__()、field、default_factory、kw_only、slots、frozen、match_args 与常用辅助函数。

Python 爬虫如何模拟登录?本文从 Network 抓包判断 Cookie、JWT/Token 与浏览器状态,给出 requests.Session、Authorization、Playwright 三种可运行方案,并附 401/403 排查清单。

爬虫遇到 403、验证码、IP 被封怎么办?本文从代理 IP 原理、requests proxies 写法、账号密码认证、短效代理和隧道代理选择、失败重试与合规边界讲清排查思路。

本文用 TraceCloud 第 15 到第 18 关串起 CSS 偏移、CSS content、固定字体映射和动态字体反爬,重点讲清自定义字体、Unicode 私有区、WOFF2、fontTools、cmap 和字形轮廓比对的完整处理思路。

本文从 requests.Session 的状态保持机制出发,说明 Cookie、验证码接口、失败重试和 403 排查之间的关系,适合需要处理登录态、验证码校验或翻页采集的 Python 爬虫场景。

aiohttp 怎么用?本文从 GET、POST、params、headers、响应读取讲到超时、异常处理、并发控制、连接池和重试封装,适合写 Python 异步爬虫和批量接口请求。

面向爬虫和 Web 自动化学习者的 Playwright Python 入门教程,覆盖安装、同步与异步模式、元素定位、等待策略、上下文管理、网络拦截、截图调试和实践建议。

XPath 是爬虫里精准定位网页元素的核心技能,本文从节点选取、谓语、轴运算到 Python lxml 实战,全面讲解 XPath 语法与避坑指南。

Python Parsel 怎么用?本文通过可运行示例讲清 Selector、CSS、XPath、正则提取、列表页解析及空结果排查,并给出 Parsel 配合 requests 的完整写法。

urljoin 是 Python 爬虫处理相对路径拼接的核心工具。本文从 URL 结构讲起,覆盖相对路径、绝对路径、./、../、urlparse、urlunparse 在爬虫中的实战用法,附 6 个实战案例与常见报错解决方案。

梳理 requests 异常的完整体系,按请求阶段逐一说明 URL 错误、连接失败、超时、状态码异常和重定向异常,帮你写出不容易崩的爬虫代码。
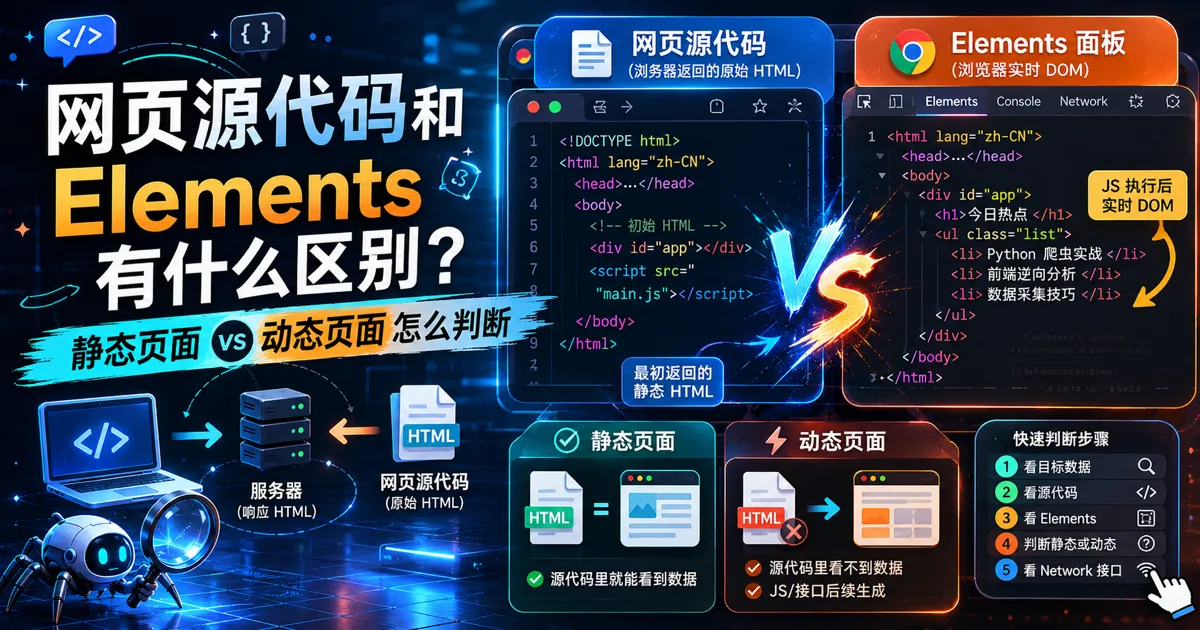
讲清网页源代码、Elements 面板和实时 DOM 的区别,说明为什么页面上看得到的数据,源代码里不一定有,以及如何判断静态页面和动态页面。