DOM 树是什么?节点、父子关系与兄弟关系详解
用爬虫初学者能理解的方式讲清 DOM 树、节点、父节点、子节点和兄弟节点,帮助你看懂网页结构并准确定位数据。
为什么要理解 DOM 树
学爬虫时,你迟早会遇到这样的问题: 页面上有很多相似的标题、图片、按钮和链接,怎么才能准确选中自己想要的那一个?
答案通常不只是“看标签名”,而是要看它在整个页面结构里的位置。
这就需要理解 DOM 树。
DOM 树能帮你回答这些问题:
- 某个元素在页面结构的哪一层?
- 它的外层容器是谁?
- 它旁边有哪些同级元素?
- 它内部还有没有更深层的子元素?
- 选择器为什么能选中它,或者为什么选不中它?
DOM 是什么
DOM 全称是 Document Object Model,中文通常叫文档对象模型。
你可以把它理解为:浏览器把 HTML 文档解析后,生成的一棵结构树。
HTML 源代码是文本,浏览器不能只把它当普通字符串处理。 浏览器会把标签、属性、文本、注释等内容解析成一个个节点,再按嵌套关系组织起来。
这棵树,就是 DOM 树。
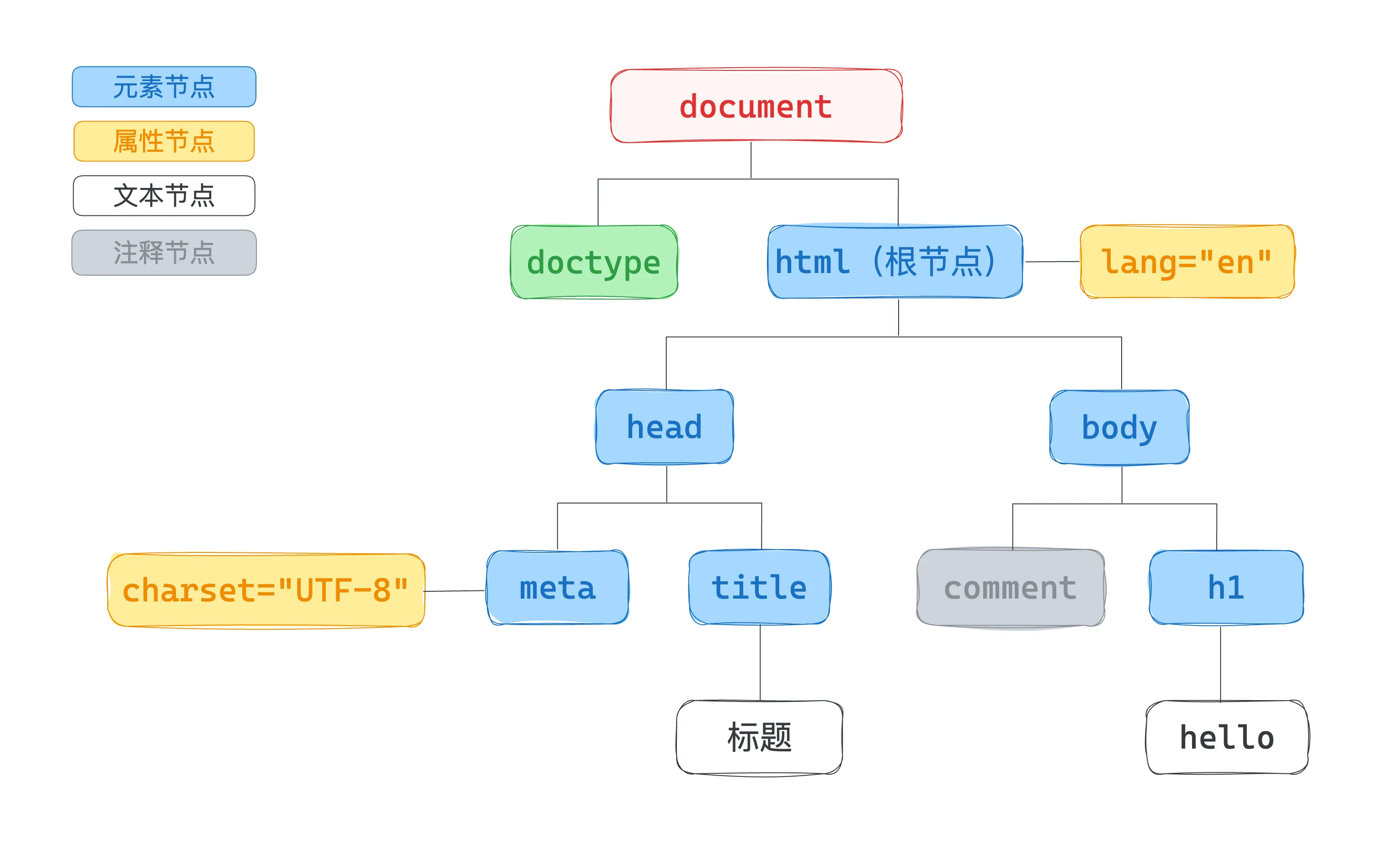
什么是节点
在 HTML 中,很多东西都可以被看作节点(Node),例如:
- 文档本身是节点。
- 元素是节点,例如
html、head、body、h1、p。 - 属性也可以被理解为节点信息,例如
id、class、href。 - 文本是节点,例如标题里的文字。
- 注释也是节点。
例如下面这段 HTML:
<div class="container">
<h1 id="title">爬虫你好</h1>
<p>这是一个段落。</p>
<a href="https://www.xfei.tech">访问文档</a>
</div>
可以简单理解为:
div是一个元素节点。h1、p、a是div里面的子元素节点。class="container"、id="title"、href="..."是节点上的属性信息。爬虫你好、这是一个段落。、访问文档是文本内容。
父节点、子节点和兄弟节点
DOM 树最重要的是节点关系。 新手先掌握三种关系就够了:
- 父节点
- 子节点
- 兄弟节点
父节点:包住当前节点的上一层
如果一个元素在另一个元素里面,那么外层元素就是它的父节点。
<body>
<h1>爬虫你好</h1>
</body>
在这段结构里,body 是 h1 的父节点。
子节点:被当前节点直接包住的下一层
反过来看,h1 是 body 的子节点。
如果一个节点直接出现在另一个节点内部,它就是直接子节点。
<div class="card">
<img src="/movie.webp" alt="电影封面" />
<h2>电影标题</h2>
</div>
这里 img 和 h2 都是 div.card 的子节点。
兄弟节点:拥有同一个父节点的同级节点
如果多个元素被同一个父元素包住,它们就是兄弟节点。
<div class="card">
<h2>电影标题</h2>
<p>电影简介</p>
<a href="/detail">查看详情</a>
</div>
这里 h2、p、a 都在同一个 div.card 里面,所以它们是兄弟节点。
DOM 树为什么是一棵树
HTML 是层层嵌套的结构。
一个文档里有 html,html 里有 head 和 body,body 里又有各种标题、段落、图片、按钮。
它看起来就像一棵倒过来的树:
document是整棵树的入口。html是页面的根元素。head和body是html的子节点。body下面继续分出更多内容节点。
除了根节点外,每个节点通常都有自己的父节点,也可能拥有多个子节点或兄弟节点。
DOM 树和选择器有什么关系
选择器的本质,就是在 DOM 树里找到目标节点。
例如:
.container img {
border-radius: 12px;
}
这句 CSS 的意思不是“随便找一张图片”,而是:
- 先找到类名为
container的元素。 - 再去它内部找所有
img后代元素。
这就是基于 DOM 层级关系的查找。
再看一个例子:
.card > img {
width: 160px;
}
这里的 > 表示只找直接子元素。
如果图片藏在更深层的 div 里面,就不会被选中。
所以,想写准选择器,就必须先看懂 DOM 树。
爬虫里怎么利用 DOM 树
假设页面结构是这样的:
<div class="movie-card">
<img src="/cover.webp" alt="电影封面" />
<h2 class="title">星际穿越</h2>
<p class="score">9.4</p>
<a class="detail" href="/movie/1">查看详情</a>
</div>
如果你要抓电影标题,不能只想“抓 h2”,因为页面上可能有很多 h2。
更稳的思路是:
- 先定位每一个
.movie-card。 - 再在每个卡片内部找
.title、.score、.detail。 - 把同一个卡片里的标题、评分、链接组合成一条数据。
这就是爬虫里非常常见的“先定位列表项,再提取字段”的思路。
常见误区:只看页面,不看结构
浏览器展示出来的是视觉结果,DOM 树展示的是结构关系。 视觉上挨得很近的两个元素,不一定在 DOM 中就是兄弟节点;视觉上隔得很远的元素,也可能在同一个父容器里。
所以爬虫调试时,不要只凭页面肉眼判断。 更可靠的做法是打开开发者工具,在 Elements 面板里观察真实结构。
建议养成这个习惯:
- 先选中页面上的目标文字。
- 在 Elements 面板里查看它所在的标签。
- 向上找外层容器。
- 判断它和其他字段之间的父子、兄弟关系。
- 再决定用什么选择器。
总结
DOM 树是浏览器理解网页结构的方式,也是爬虫定位数据的地图。
你只要先掌握这三组关系:
- 父节点:外层包住当前节点的节点。
- 子节点:当前节点直接包住的下一层节点。
- 兄弟节点:拥有同一个父节点的同级节点。
再配合 CSS 选择器,就能从“看见页面”进一步走到“准确定位数据”。 这一步打牢后,后面学 HTML 解析、XPath、CSS Selector 和动态页面抓包都会更轻松。
Practice