HTTP 协议入门:请求、响应、状态码(爬虫视角)
从爬虫初学者最常见场景出发,讲清 HTTP 请求与响应的结构、状态码的判断方法,以及抓包时应该优先看哪些字段。
为什么爬虫一定要先学 HTTP
爬虫本质不是“神秘技术”,而是一个自动发请求、收响应的客户端程序。 你能不能把请求发对、把响应看懂,直接决定了爬虫项目能不能跑起来。
所以在学代码之前,先吃透 HTTP 的通信格式,后面抓包、接口复现、反爬排查都会轻松很多。
HTTP 的两个核心特性
- 无状态:每次请求默认独立,服务端不会天然记住你上一次做过什么。
- 文本协议(HTTP/1.x 视角):请求与响应按规范组织成可读文本结构。
无状态意味着什么? 你上一次请求成功,不代表下一次自动成功。Cookie、Token、会话参数,都需要你在后续请求里明确带上。
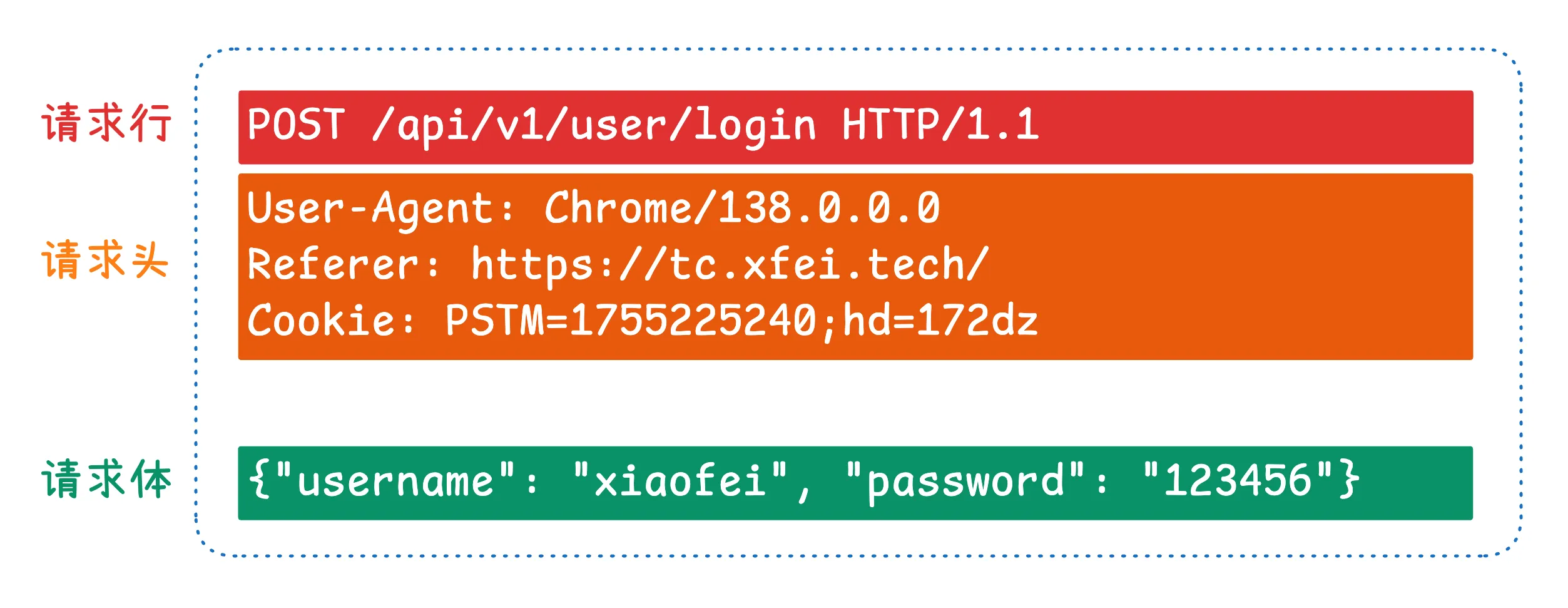
请求报文怎么读:三段式结构
一个完整 HTTP 请求可分为三部分:
- 请求行
- 请求头
- 请求体
其中,请求头和请求体之间必须有一个空行,这是协议格式要求。
1)请求行:先看“你要做什么”
请求行通常包含:请求方法 + 路径 + 协议版本。 爬虫里最常见的方法是:
GET:拿数据POST:提交数据
很多登录、注册、搜索提交会用 POST,并把参数放进请求体。
2)请求头:再看“你是谁,从哪来”
请求头是键值对集合,用来补充请求上下文。初学爬虫先重点看这几个:
User-Agent:声明客户端环境(浏览器/系统)。Referer:说明当前请求来源页面。Cookie:携带会话态与业务标识。
请求失败时,先别急着改代码,先对比浏览器和脚本这三个头是否一致,往往就能快速定位问题。
3)请求体:业务数据放这里
请求体是提交给服务端的业务内容。
GET 通常没有请求体,POST 更常见有请求体。
响应报文怎么读:同样三段式
响应结构也分三部分:
- 响应行
- 响应头
- 响应体
响应头和响应体之间同样有空行分隔。

响应行:状态判断的第一现场
响应行包含:协议版本 + 状态码 + 状态描述。 在爬虫排错里,状态码是第一优先级信息。
常见状态码速查(爬虫高频)
2xx:成功
200 OK:请求成功并返回结果。
3xx:重定向
301 Moved Permanently:永久重定向,浏览器通常会缓存。302 Found:临时重定向,通常每次都要重新请求旧地址。
4xx:客户端请求问题
400 Bad Request:请求格式或参数错误。401 Unauthorized:未授权,常见于未登录或登录失效。403 Forbidden:请求被拒绝,常见于权限不足或风控拦截。404 Not Found:路径错误或资源不存在。429 Too Many Requests:请求过快,被限流。
5xx:服务端错误
500系列通常表示服务端内部处理失败。
更多状态码参考: MDN HTTP 状态码文档
一个实战中常见的坑
状态码 200 不等于业务成功。
很多站点会返回 200,但在响应体里给出“未登录”“签名错误”“访问频繁”等业务错误信息。
所以排错顺序建议固定为:
- 先看状态码
- 再看响应头(例如
Content-Type) - 最后看响应体的真实业务内容
给初学者的请求排查流程
遇到“脚本拿不到数据”时,按这个流程走:
- 在浏览器开发者工具定位同一请求。
- 对比 URL、方法、参数是否一致。
- 对比关键请求头:
User-Agent、Referer、Cookie。 - 对比状态码与响应体错误提示。
- 观察是否出现
301/302跳转或429限流。
这个流程跑通后,你会发现大多数“玄学问题”都能落到明确字段差异上。
总结
学 HTTP 不是背概念,而是为了把请求发送和响应解读变成可重复的工程动作。 把请求结构、响应结构、状态码这三块打牢,爬虫入门就完成了一半。
Practice