URL 是什么?从客户端与服务器讲透爬虫第一步
面向爬虫初学者,系统讲清客户端和服务器的通信关系、URL 的 6 个组成部分,以及 URL 编码在实战中的作用。
先建立一个最重要的认知
爬虫不是“黑科技”,它本质上只是一个模拟客户端发请求的程序。 你在浏览器里点开网页,和你在 Python 里请求网页,底层都在做同一件事:客户端向服务器要资源。
所以在写任何爬虫代码之前,先把这套通信模型吃透,会让后续学习快很多。
客户端和服务器,到底是谁在做什么
在网络通信中,永远有两个角色:
- 客户端(Client):发起请求的一方。
- 服务器(Server):接收请求并返回结果的一方。
你常用的浏览器就是客户端,网站背后的应用服务就是服务器。 这也是为什么我们常说 B/S(Browser/Server)架构,本质上仍然是 C/S(Client/Server)架构。
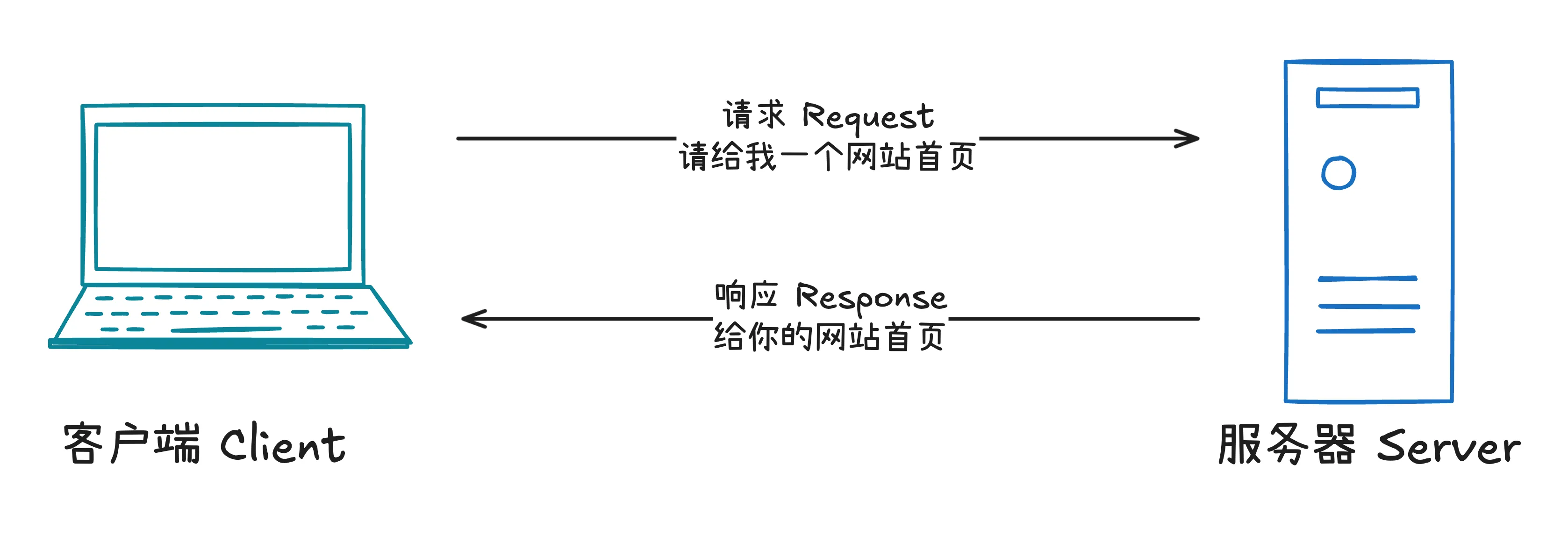
把它放到爬虫语境里就更直观了:
- 你写的爬虫程序 = 客户端。
- 目标网站 = 服务器。
- 你请求页面/接口 = 发起 Request。
- 网站返回 HTML/JSON/图片 = 返回 Response。
这就是一轮完整的爬虫工作流。
URL 是什么,为什么它是爬虫定位资源的核心
URL 全称是 Uniform Resource Locator(统一资源定位符),也就是我们日常说的网址。 它的作用是告诉客户端:去哪里、用什么方式、拿什么资源。
一个完整 URL 通常可以拆成 6 部分:
- 协议(Protocol / Schema)
- 主机(Host)
- 端口(Port)
- 路径(Path)
- 参数(Query / Param)
- hash(锚点)

1)协议:先约定通信规则
协议就是通信格式,比如 http 或 https。
你可以把它理解为“双方说话前先统一语法规则”。
在爬虫里最常见的就是 HTTP(S) 协议,后续我们抓接口、带请求头、带 Cookie,都是在这套规则里工作。
2)主机:找到目标机器
主机就是你要访问的那台计算机,对应两种常见形式:
- IP 地址:网络中的机器编号。
- 域名:便于记忆的别名(会经 DNS 解析为 IP)。
也就是说,你输入域名访问网站时,浏览器会先帮你“翻译”到对应 IP,再去连接服务器。
3)端口:找到目标服务
一台机器上可能同时跑很多服务,所以只知道 IP 还不够。 端口就像同一栋楼里的门牌号,帮你找到具体服务进程。
端口可以省略,客户端会按协议自动补默认值:
http默认80https默认443
4)路径:告诉服务器你要哪份资源
路径用于标识具体资源或服务入口。 例如:
/通常表示首页资源。/list可能是列表服务。/api/v1/items可能是接口资源。
同一个站点,不同路径往往对应不同业务能力。
5)参数:传递额外条件
参数用于补充请求条件,常见于搜索、分页、筛选:
http://movie.com/list?page=3&size=20
上面这个 URL 的参数表达了两件事:
- 请求第 3 页
- 每页 20 条
多个参数用 & 连接,键值使用 key=value 形式。
6)hash:更多是浏览器侧定位
# 后面的 hash 一般用于前端页面内部锚点跳转,通常不参与服务器资源定位。
在多数爬虫请求里,hash 不是关键点。
URL 编码:为什么中文会“变成一串百分号”
URL 中不能直接出现非 ASCII 字符(比如中文)。 当你搜索中文关键词时,浏览器会自动把中文转成编码形式,这就是 URL 编码(Percent-Encoding)。
例如中文关键词会被编码成 %E4%BA%91%E9%9F%B5 这类字符串。
在 Python 中,你可以这样编码和解码:
from urllib.parse import quote, unquote
keyword = "云韵"
encoded = quote(keyword)
decoded = unquote(encoded)
print(encoded) # %E4%BA%91%E9%9F%B5
print(decoded) # 云韵
实战里很多 HTTP 客户端库会帮你自动编码,但你要知道这个机制,否则排查请求失败时会非常被动。
给爬虫初学者的一套 URL 分析步骤
拿到任意一个网址,先按下面 5 步拆解:
- 看协议:HTTP 还是 HTTPS。
- 看主机:目标站点是谁。
- 看路径:对应哪个页面或接口服务。
- 看参数:哪些是必传参数,哪些是可选参数。
- 做最小化实验:逐步删减参数,验证服务是否还能正常返回。
这套步骤能帮你快速识别“请求最小闭环”,是后续接口分析、请求复现、反爬排查的基础能力。
总结
如果把爬虫学习看成盖楼,客户端/服务器 + URL 就是地基。
理解了这篇里的核心点,你就能更稳地进入下一步:抓包、请求复现、参数分析和自动化采集。
一句话收尾:先学会读 URL,再学会发请求,最后再谈爬虫工程化。
Practice